
The Lectical Scale
The Cutting-Edge in Developmental Psychometrics

By the early 2000s, constructivist researchers had progressed from early models like Piaget’s stages of cognition, to stage models in various domains (e.g., morality, value, identity, faith), to a seemingly universal scale of hierarchical complexity of around 13 levels that—potentially, it seemed—might be able to measure complexification in any domain.
The researcher who would turn this potential into reality was Theo Dawson. A colleague of Fischer and Commons, Dawson recognized the prospect for hierarchical complexity to offer a truly universal measure of human learning across different domains and, through a series of papers in the early 2000s, laid the ground for this with impressive rigor. Using datasets of hundreds of scored interviews, and methods like factor and Rasch analysis,[i] she showed that various domain-specific stage measures (e.g., Kohlberg’s Standard Issue Scoring System, Kitchener and King’s Reflective Judgment Scoring System, Armon’s Good Life Scoring System) all appeared to be tapping the same fundamental variable: hierarchical complexity—the deeper “core structure” organizing all their domain-specific content (see Figure 2.6).[ii]
Figure 2.6. Alignment of Different Domain-Specific Models[iii]
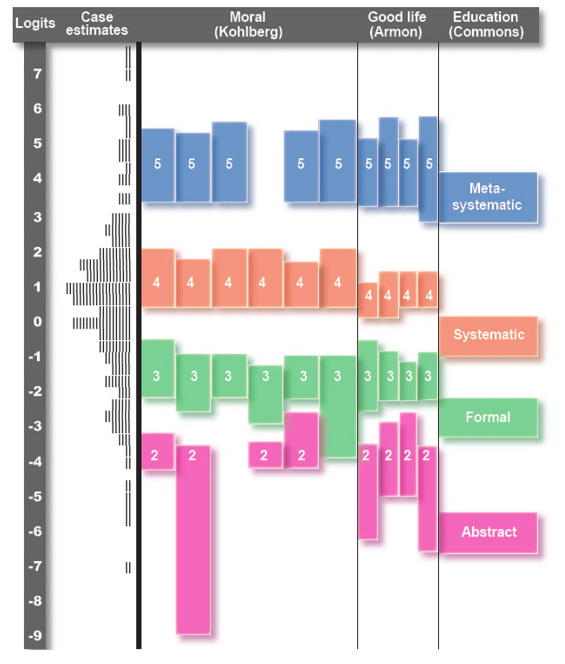
This analysis has been profoundly illuminating, as having a universal complexity “ruler” would allow us to show not only how earlier models align along this axis but also where they have been out of alignment or mistaking content for structure.[iv] Using hierarchical complexity as our standard measure, we can assess performances purely at the level of the structure organizing their meaning.[v] When we do, we can then see how the content from different domain-specific stage models reflect the same levels of complexity.[vi]

What was really needed, then, was not multiple different, content-based, manual scoring systems, but a single, general evaluation tool that could efficiently score performances in any domain for hierarchical complexity. In 2004, Dawson published exploratory work on a fully computerized scoring system of this kind.[vii] Piloted as the Lexical Abstraction Assessment System (LAAS), which would later become the Computerized Lectical Assessment System (CLAS), this automated scoring system aimed to provide the most objective, scalable, and refined common scale yet for measuring hierarchical complexity.
As the name suggests, scores were based on a form of lexical analysis, meaning it scored texts by assessing the specific words they used to convey meaning.[viii] By systematically generating empirically-based lists from the actual language of over 1,000 scored texts, Dawson was able to use patterns in vocabulary distribution to correctly predict the hierarchical complexity of texts with a high rate of accuracy.[ix] Based on these findings, she concluded that hierarchical complexity level for text performances could indeed be scored through computer analysis just as reliably as human scorers.[x]
This experiment marked a major breakthrough for complexity scoring using linguistic analysis—both practically and theoretically. Practically, it suggested that such a system could be deployed at scale as a reliable evaluation method for all manner of learning assessments. Theoretically, though, its implications were even more interesting, for it showed that hierarchical complexity could be assessed at the level of word use and their meanings. Human language has a complexity axis, and that complexification can be tracked through levels of growing abstraction. And, because such a progression follows the logic of hierarchical integration, whereby later content emerges by building upon earlier content, the sequence represents a developmental process. In our terms: hierarchical complexity measures Symbolic Learning.
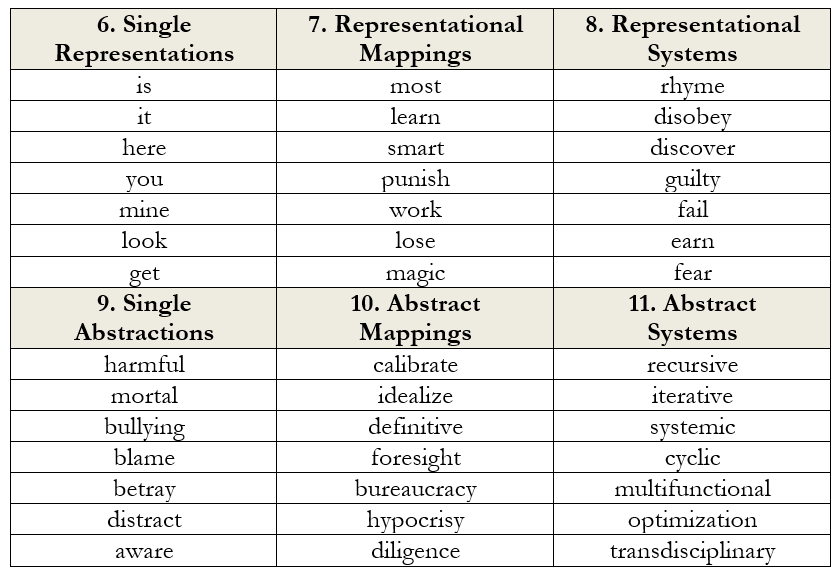
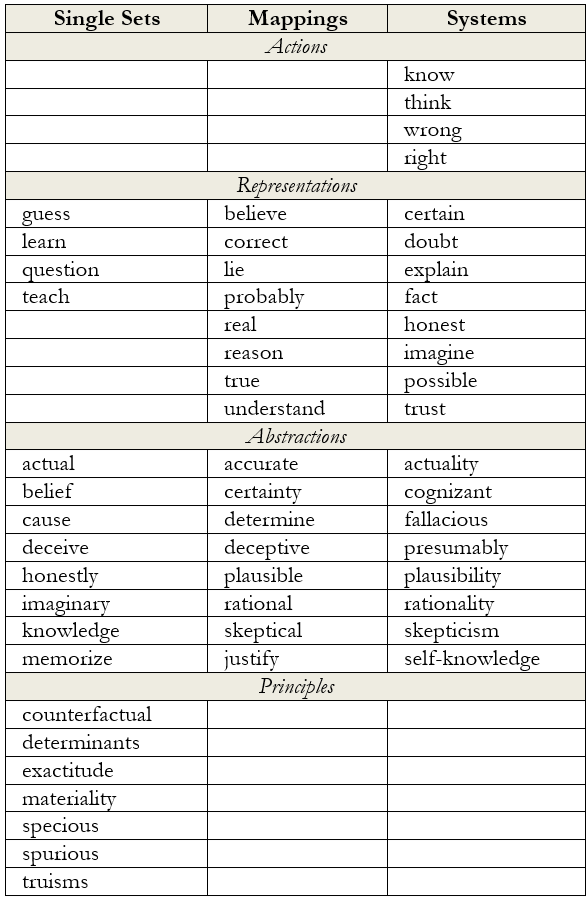
Building upon her early successes, Dawson would spend the next two decades developing an extensive “dictionary” of such semantic items carefully organized according to complexity level. Today, this Lectical Dictionary contains over 40,000 items (and counting) based on nearly 100,000 scored texts. Each represents a semantic unit that has been meticulously indexed to a complexity level through a process called “lexicating.” Dawson describes the process this way:
The Dictionary is composed of units of meaning called Lectical Items — words or phrases like “evidence” or “reliable evidence” that carry specific meanings. Each Lectical Item is assigned to a Lectical Phase (1/4 of a Lectical Level), based on a combination of empirical evidence, the judgment of our analysts, and a variety of helper algorithms. The goal is to assign items to the lowest level at which the simplest meaning they carry is likely to be useful. Dictionary entries begin with first speech and cover the full span of development.[xi]
Table 2.9. Examples of Items in the Lectical Dictionary[xii]
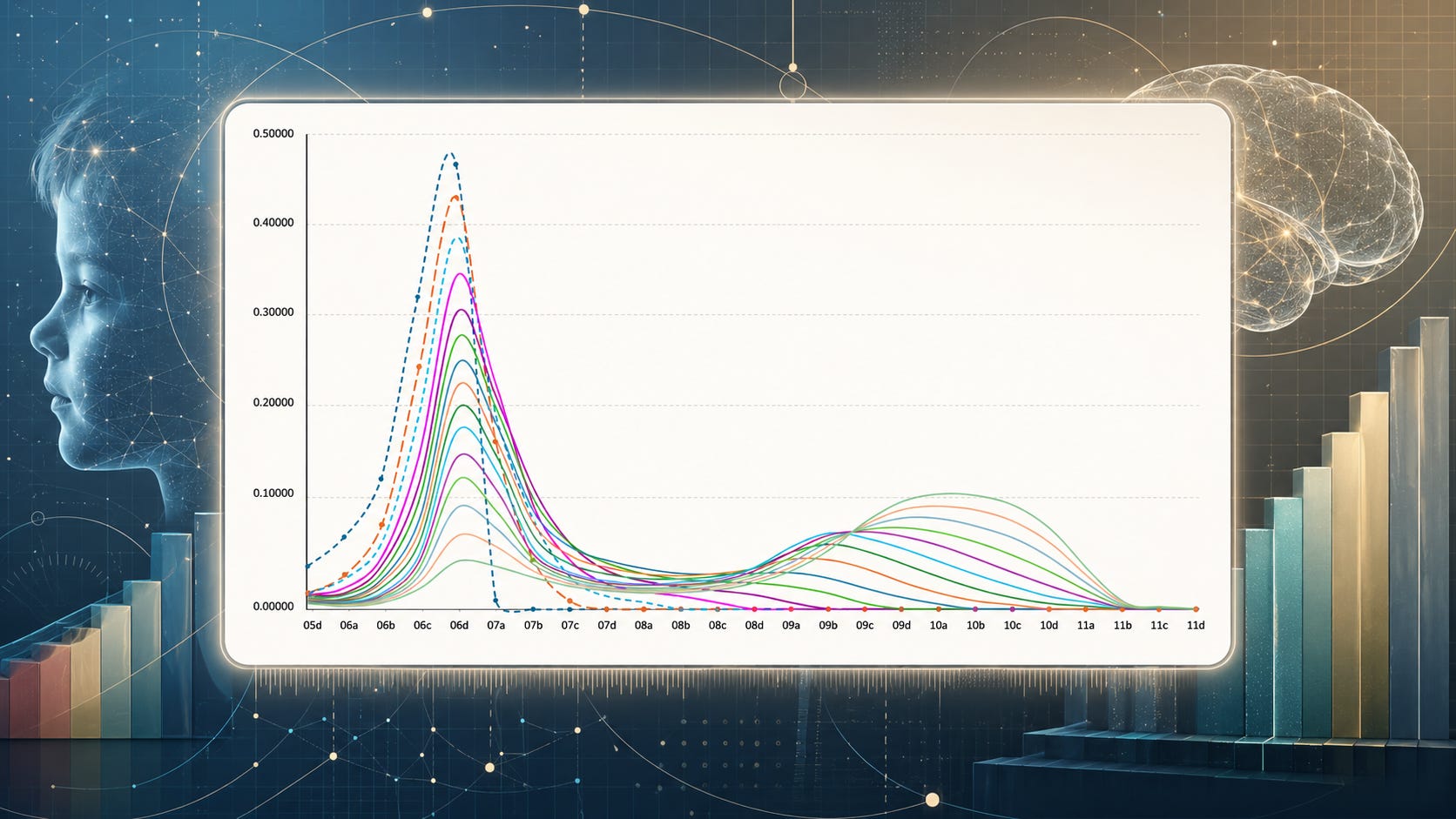
Using the Lectical Dictionary, CLAS analyzes texts to see what range of complexity levels is represented by their language use. By assessing the density distribution curve in this way, the algorithm can award precise numerical scores within Levels.
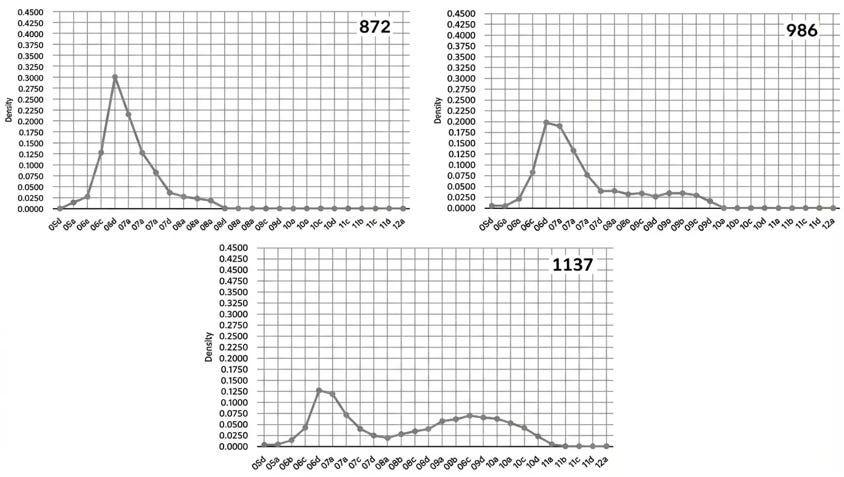
Figure 2.7 presents some examples of such curves. Here, the top left graph shows a curve that tapers off at Lectical Phase 8c, with no meanings expressed at Level 9 or above, generating a score at 872. The top right graph, by comparison, evidences meanings reaching into late Level 9 before tapering off; it scores at 986. Finally, the bottom graph shows a high-scoring text with a growing bulk of meanings that ultimately bottom out in Phase 11b; it scores at 1137.
Figure 2.7. CLAS Density Distribution Curves of Different Texts[xiii]
The empirical curve of a linguistic performance is matched for best fit against the standardized curves of CLAS’s measuring system, which, like a ruler for length or a thermometer for heat, provides the idealized metrical units for hierarchical complexity.
Clearly, this method allows for much more fine-grained scoring of developmental levels, offering a measuring rod of unprecedented granularity. Indeed, if Piaget’s stage model had given us a yardstick by which to measure development, and Fischer and Commons’s scales of hierarchical complexity gave us feet, then Dawson and the Lectical Scale have given us millimeters. For here, each of the levels of hierarchical complexity (already much more refined than Piaget’s stages) is measurable on a 100-point scale (see Table 2.10).[xiv]
Table 2.10. Lectical Levels Compared to Dynamic Skill Levels
Practically speaking, qualitative differences are usually only detectable at the Phase level, and scores are probably best treated with an error margin of around ±10 points. Moreover, scoring does not obviate the need for human interpretation of texts and the hermeneutic assessment of conceptual depth; rather, it opens up mixed-methods approaches that can ground qualitative readings in quantitative data.
All said, Lectica’s measurement capabilities represent the cutting-edge in cognitive-developmental psychometrics and, to my mind, the culmination of the constructivist tradition in psychology to date. While earlier stage models did their best while struggling in the dark to separate objective development from superficial content distinctions, hierarchical complexity analysis based on Lectical scoring gets at the structural core of performances, allowing us to better parse developmental structure from the specific content of people’s thinking. Doing so allows us to reconsider the developmental trajectories mapped by various earlier stage models in terms of hierarchical complexification within specific domains.
This is nothing less than a revolution for neo-Piagetian developmental psychology, as it offers the first truly objective, domain-general measure of structural development, allowing us to assess whether older domain-specific models do indeed track complexification along this common axis, and, if so, in precisely what manner.
Such methods stand to significantly update our developmental models, leaving behind the simple conception of linear stages in favor of dynamic skills or capacities that can be measured by a common complexity scale. Indeed, the remainder of this volume will be dedicated to just this sort of effort, examining developmental models related to human meaning-making through the lens of Symbolic Learning as hierarchical complexification.
Here, moreover, the granularity of Lectical scoring can actually allow us to track how the meanings of specific concepts develop. Consider, for instance, the complexification of the idea of “evidence” as documented by a wide array of performance findings and the lexication process (Table 2.11).
Table 2.11. Complexifying Conceptions of “Evidence”[xv]

Such “learning pathways” for particular ideas chart the way their meanings complexify through Symbolic Learning. Writing about these “progressions in the development of [a concept’s] meaning” in a 2020 paper, Dawson observes:
Longitudinal and cross-sectional analyses of sequences like this one has demonstrated that each successive conception builds upon previous conceptions (Dawson & Gabrielian, 2003; Dawson-Tunik, 2004). These findings are consistent with the developmental theory upon which the Dictionary is based (Piaget, 1985; Fischer, 1980), and suggest that Lectical Items assigned to a particular phase can be said not only to represent the understandings of that phase but also the building blocks for future conceptions. The distribution of Lectical Items from different phases within a given performance can therefore be thought of as evidence of the historical pattern of an individual’s development.[xvi]
In short, conceptual meanings deepen in richness and sophistication by building upon earlier, simpler forms of meaning—a process measurable through Lectical analysis. Ideas reach into higher levels of abstraction and sophistication by building off existing knowledge, including earlier levels in a more expansive frame. Such levels then become the basis of higher levels, and so on.
From the tradition’s early insights in the work of giants like Baldwin and Piaget, to refined models of hierarchical complexity by Fischer and Commons, to the development of extremely precise metrics based on those refinements by Dawson and her colleagues, constructivist accounts of human learning have helped reveal, in ever-increasing detail, how knowledge develops and complexifies. Today, genetic epistemology is less an orienting framework and more a well-charted map. The question before us now, then, is how we might use such a map to better understand the evolution of meaningful knowledge as it develops in the human psyche.
NEXT: MEANINGFUL HUMAN KNOWLEDGE
NOTES
[i] See G. Rasch, Probabilistic Model for Some Intelligence and Attainment Tests (Chicago: University of Chicago Press, 1980). Rasch modelling is a mathematical framework used in psychometrics to analyze how a person’s characteristics relate to their probability of answering a particular item correctly. As Dawson and colleagues put it in a 2005 article:
These models are designed specifically to examine hierarchies of person and item performance, displaying both person proficiency and item difficulty estimates along a single interval scale (logit scale) under a probabilistic function. In addition, they can be employed to test the extent to which items or scores conform to a theoretically specified hierarchical sequence. A central tenet of stage theory is that cognitive abilities develop in a specified sequence, making the statistical tests implemented in a Rasch analysis especially relevant to understanding stage data. The Rasch model permits researchers to address questions like, “Are all single abstractions items more difficult than all representational systems level and less difficult than all abstract mappings items? (Theo L. Dawson-Tunik et al., “The Shape of Development,” European Journal of Developmental Psychology 2, no. 2 (2005): 172)
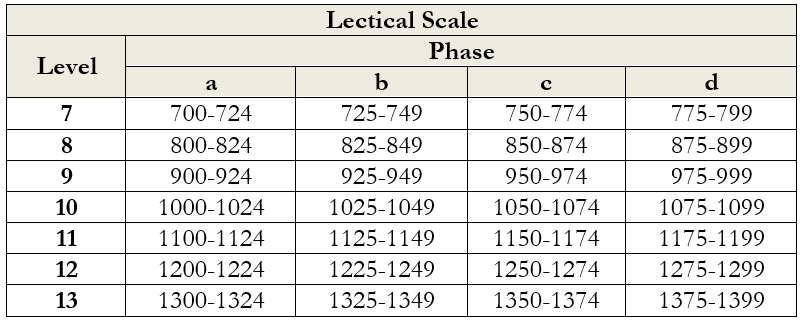
If a stage model evinces hard stage behavior, the distinct levels should not exhibit broad overlaps and high variance (as in the first figure below) but instead should show clearly discontinuous probability curves (as in the second figure) (ibid., Figure 2 and 3).
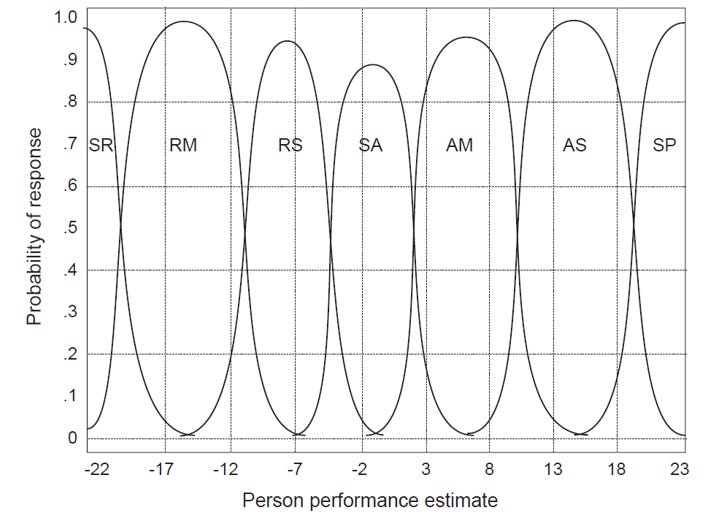
Rasch modeling helps ensure proper calibration of item difficulty and assessment of performances in such a way as is required of genuinely hard stage models.
Using this method, Dawson has demonstrated a robust meeting of hard stage requirements for the scale of hierarchical complexity such as is employed by Fischer and Commons and now refined into the Lectical Scale. The below figure shows the clear differentiation of the scale’s hard stages (RM = representational mappings, RS = representational systems, SA = single abstractions, etc.) (ibid., Figure 5).
[ii] In one study, 637 moral judgment interviews were scored according to both Kohlberg’s Standard Issue Scoring System (SISS) and the Hierarchical Complexity Scoring System (HCSS), demonstrating a correlation of .88 between the two systems (Theo Dawson, “A Stage Is a Stage Is a Stage: A Direct Comparison of Two Scoring Systems,” The Journal of Genetic Psychology 164, no. 3 (2003): 335–364). A similar study of 378 interviews found a disattenuated correlation of .92, based on an inter-rater reliability between 80% and 97% within half a complexity order. See also Dawson et al. “Domain-General and Domain-Specific Developmental Assessments: Do They Measure the Same Thing?,” Cognitive Development 18 (2003): 61–78); Theo Dawson, “A Comparison of Three Developmental Stage Scoring Systems,” Journal of Applied Measurement 3 (2002): 146–189.
In sum, “the cumulative evidence,” writes Dawson,
indicates that over 80% of the variance between scores awarded with the hierarchical complexity scoring system and these other scoring systems is explained by a shared dimension. Taking into account the random noise introduced by measurement error, this leaves little variance for the content dimension to explain—arguably, too little to support the claim that good life and moral reasoning represent unique structures. One way to think about these results is to consider that the Good Life Scoring System and Standard Issue Scoring System, rather than measuring unique domain-specific stage structures, actually assess hierarchical complexity within the moral and good life domains, while adding surface structure and content requirements for stage assignment. (Theo Dawson, “Layers of Structure: A Comparison of Two Approaches to Developmental Assessment,” Genetic Epistemologist 29, no. 4 (2001): 13)
[iii] Theo Dawson, “Validity and Reliability of the LAS,” 2013, presentation slides.
[iv] For example, we can see in Figure 2.6 that Kohlberg’s moral reasoning stages 3, 4, and 5 align closely with hierarchical complexity orders 10, 11, and 12 (Formal, Systematic, Metasystematic), with considerable gaps between them and no overlaps (as we should expect to find of hard stages assessed using Rasch analysis). This neat correspond-ence begins to break down, however, towards the lower stages. Notably, various researchers had already identified problems with Kohlberg’s first two stages owing to the age of his research sample. This analysis helps reveal that his Stage 2 should be matched to Level 9. Abstract. Dawson notes:
The failure of the Standard Issue Scoring System to adequately assess the lower stages has been addressed by several researchers. For example, Kuhn (1976) and Damon (1977) have argued that Kohlberg’s instrument is inappropriate for assessing the moral judgment of children and that it results in underestimates of children’s moral competence. Also, Keller, Eckensberger, and van Rosen (1989) showed that Kohlberg’s Moral Stages 1 and 2 fail to account for a wide range of moral concepts expressed by young children and that it generally underestimated their ability to take the perspective of others. Dawson and Gabrielian (2003) also have expressed concern about the limitations of Kohlberg’s construction sample. They argued that not only was the sample small, but the youngest respondents were only 10 years of age at the time of the initial interviews. By 10 years of age, most children from Western cultures are performing at the first level of what Fischer (1980) calls the abstract tier, which is considered analogous to Piaget’s early formal operations (Ginsburg & Opper, 1988). Yet Kohlberg’s Moral Stage 2 was considered analogous to Piaget’s concrete operations (Colby & Kohlberg, 1987b).
In light of these issues, it is clear why Kohlberg’s stages map the way they do to hierarchical complexity orders.
[v] See Dawson, “Layers of Structure: A Comparison of Two Approaches to Developmental Assessment,” 2–14.
[vi] As Dawson puts it in “A Stage Is a Stage Is a Stage,” 344:
Kohlberg and his colleagues attempted to distinguish between structure and content in their stage definitions; however, their scoring system relies on a concept-matching strategy. Consequently, it is difficult to ask questions about the relationship between structure and content except in the limited sense of asking how moral stage is related to performance on a given issue, element, or norm. The Hierarchical Complexity Scoring System takes the separation of structure and content a step further. When scoring with the Hierarchical Complexity Scoring System, particular conceptual content is the focus only to the extent that it reveals the hierarchical order of abstraction of a performance; therefore, complexity-order assignment and conceptual analyses can be conducted separately.
Such a separation then allows specific content to be deductively related to hierarchical complexity level, rather than vice versa. This makes the construction of domain-specific hard stage models more rigorous..
[vii] See T. L. Dawson and M. Wilson, “The Laas: A Computerized Scoring System for Small- and Large-Scale Developmental Assessments,” Educational Assessment 9, no. 3&4 (2004). Dawson notes:
The evaluation of developmental interventions has been hampered by the lack of practical, reliable, and objective developmental assessment systems. Most cognitive-developmental evaluation methods are expensive and time-consuming to implement. Moreover, they are task- and domain-specific, which means that the range of behaviors that can be evaluated developmentally is restricted. These limitations make developmental assessments impractical for most real-world applications. (153)
[viii] More accurately, analysis is based on “semantic units,” which can range from single words to short phrases. The theoretical insight that makes this sort of assessment possible for hierarchical complexity scoring is the recognition that such semantic units and their logical organization can be indexed to specific complexity levels, while the distribution of their densities in a performance can then be used to rate an overall performance. As Dawson wrote in the 2004 pilot study:
Because individual lexical items (individual words as well as hyphenated items, like social contract and self-understanding) stand for concepts that embody a hierarchical order of abstraction, it is possible to classify many lexical items according to the hierarchical complexity of the underlying concepts they represent. This makes it possible to classify individual lexical items according to their hierarchical order of abstraction. Because each complexity order is associated with a secondary order of abstraction, it is possible to classify lexical items into one list per complexity order. We hypothesized that a set of lists of this kind, which we called abstraction indexes, could be employed to assess the hierarchical complexity of texts, because patterns in the distribution of lexical items would differ from order to order. (ibid., 168)
[ix] Dawson’s pilot study used 1,014 texts—specifically, developmental interviews collected by various researchers (e.g., Kohlberg, Commons, Armon, Dawson, etc.) between 1955 and 2003 from participants ranging from 2 to 86 years old. All were first manually analyzed and given a hierarchical complexity score by a group of trained scorers with high inter-rater agreement. Dawson relates: “We found correlations of .95 to .98 among the scores of four independent raters on a subset of 112 randomly selected texts. In this group of raters, agreement rates ranged from 80% to 97% within half a complexity order and from 98% to 100% within a full complexity order. These rates of interrater agreement equal or exceed interrater agreements commonly reported for developmental assessments” (ibid., 163). All texts were scored within 1/3 of a complexity level: 1) early transitional, 2) late transitional, and 3) consolidated. Once scored, the texts were then randomly assigned to either a Training group that would develop scoring criteria or a Test group that would evaluate these criteria (for a total of 507 texts in each group).
At this point, the total vocabulary from the texts in the Training group was parsed according to complexity level to generate the abstraction indexes: essentially, lists of words or phrases specific to Representational Mappings, Representational Systems, Single Abstractions, etc. Dawson summarizes the process:
From the vocabulary files of the training cases only, we then created eight files composed of the total vocabulary found at each complexity order. …We then employed our text analysis software to remove all of the words in the sensorimotor systems list from all of the lists representing the seven higher complexity orders. Next, we removed all of the words left in the single representations list from all of the lists representing the six higher complexity orders. Following this, we removed all of the words left in the representational mappings list from all of the lists representing the five higher complexity orders. We continued this process through the single principles order. At this point we had eight unique lists, derived empirically from the training texts we originally scored for hierarchical complexity. The lexical items in each of these lists were included simply because they occurred for the first time at the complexity order represented by the list. (ibid., 169)
In this way, lexical usage could be directly connected to complexity order to create a database of vocabulary indexed to specific complexity levels (for examples, see the below chart, adapted from Appendix C in ibid., 191).
These lists were then supplemented by synonyms and antonyms drawn from a thesaurus. By the end, the lists included 788 words for action systems; 1,771 for single representations; 1,213 for representation mappings; 651 for representational systems; 2,539 for single abstractions; 8,140 for abstract mappings; 13,754 for abstract systems; and 5,107 for single principles.
With such a database compiled, Dawson then set about testing the hypothesis that the distribution of these lexical items across performances could be used to predict overall hierarchical complexity score. For this, she ran a computer analysis of the 507 Test group texts and used the distributions of vocabulary from the abstraction indexes to see if the appearance of such terms statistically matched their earlier, manually-assessed hierarchical complexity score.
Sure enough, lexical items from the single abstractions index, for instance, rose in density beginning with texts scored at that level. This was true in all cases. The figures below show examples of the curves found.
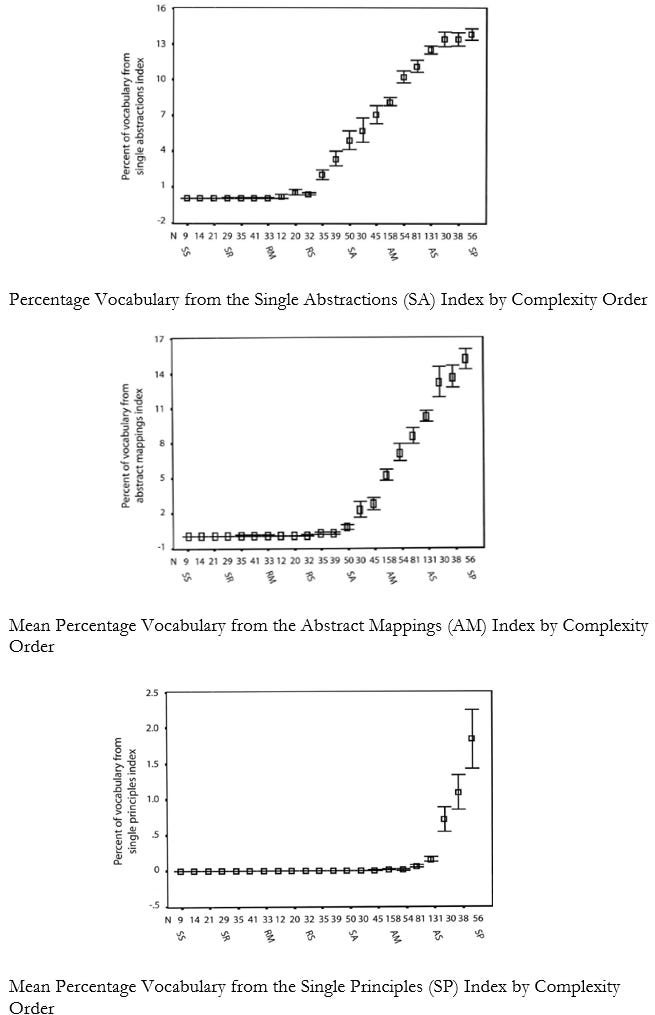
These graphs represent the total sample distributions, not just the Test cases, but Dawson notes: “Either the training sample or the test sample could have been used in place of the entire sample; The basic relationships are virtually identical” (ibid., 171).
[x] In summary, she found that
the correlation between the predicted values and human-awarded complexity orders was .98, similar to the correlation between scores awarded by different human raters. Kendall’s tau was .90, indicating that the classification rule from the earlier discriminant analysis reliably reproduced the human ratings in the test condition. Overall, the discriminant function predictions agreed with human ratings within one-third of a complexity order 81% of the time. This agreement rate is solidly within the range of human interrater agreement. When the two lowest complexity orders (sensorimotor systems and single representations), for which there were few data for estimation, were eliminated from the analysis, the discriminant function provided accurate predictions within one-third of a complexity order 83% of the time. These agreement rates meet or exceed human interrater reliabilities and agreement rates generally reported in the cognitive-developmental literature. (Ibid., 176.)
The paper concludes:
We have shown that the construct of hierarchical order of abstraction can provide the basis for accurate and reliable computerized developmental assessments. The classification rule, generated from a discriminant analysis of a set of training cases, reproduced human ratings on the test cases with a high degree of accuracy—within the range of human interrater agreement. These results suggest that, for the first time, large-scale, objective developmental assessments of text performances are feasible. (178)
[xi] See Theo Dawson, “Rethinking Educational Assessment in Light of a Strong Theory of Development,” in Handbook of Integrative Developmental Science, ed. Michael F. Mascolo and Thomas R. Bidell (New York: Routledge, 2020).
[xii] Based on information in “What Is Development & How Do We Measure It? (w/ Theo Dawson), presentation to Sky Meadow Institute,
.
[xiii] Image taken from ibid.
[xiv] Such granularity matters, as measures at this scale of analysis reveal real and significant differences in learning level and cognitive complexity. Competencies at 10a are quite different than those at 10d, and even more so at higher levels given the compounding nature of cognitive complexification. For instance, increases in advanced perspective-taking tied to cognitive complexification have been tracked using the higher accuracy and specificity of the Lectical Scale. The following figure shows results from a 2011 study by Dawson and Zak Stein on the perspective-taking skills of 254 adults.
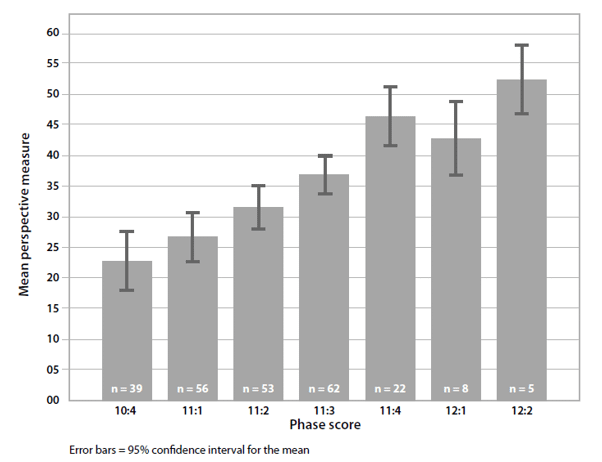
See Theo Dawson and Zak Stein, “We Are All Learning Here: Cycles of Research and Application in Adult Development,” in The Oxford Handbook of Reciprocal Adult Development and Learning, ed. C. Hoare (Oxford: Oxford University Press, 2011), 447–460.
An even more thorough analysis on this topic was undertaken by Zachary Johannes Van Rossum in 2013, whose doctoral dissertation at Columbia University analyzed 70 Lectical assessments of managerial leaders for perspective-taking and perspective-seeking capacities. Based on this data, Van Rossum identified distinct perspective-taking structures for Lectical Levels 10, 11, and 12. See Zachary Johannes Van Rossum, The Development of Social Perspective Taking and Leadership Decision-Making in City Government Managers, 2013, Columbia University.
In 2016, Clint Fuhs conducted similar research on an even larger sample of 598 leaders (A Latent Growth Analysis of Hierarchical Complexity and Perspectival Skills in Adulthood, 2016, Fielding Graduate University), while Katie Heikkinen has studied perspective-taking of 147 children across grades 3-9 (Katie Heikkinen, The Development of Social Perspective Coordination Skills in Grades 3-12, 2014, Harvard University). Such research has updated stage models of perspective-taking (such as Selman’s role-taking model) using Lectical analysis.
[xv] Dawson, “Rethinking Educational Assessment in Light of a Strong Theory of Development,” 439. The Lectical Dictionary represents the realization of Dawson’s attempt to construct a “database of developmentally organized concepts,” a “curated taxonomy of meanings” with empirical basis in thousands of actual scored assessments. Consider, for instance, how the Dictionary charts some of the ways the meanings of “truth” differentiate through the learning-as-complexification process.
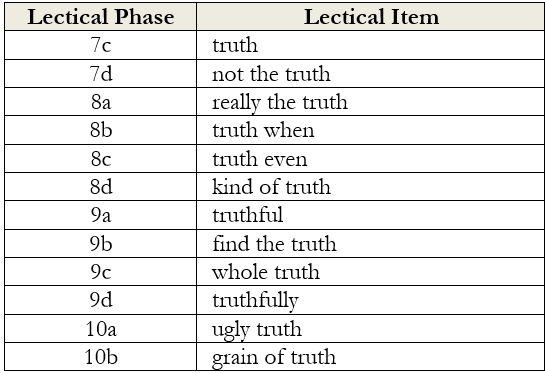
For an analysis of how the meanings of various scientific concepts evolve, see Theo Dawson and Zak Stein, Mind, Brain, & Education: Final Report, Lectica Institute (2006).
[xvi] Ibid; italics added.
Brendan, thanks as always. The one concern that comes to mind is that when you become actively aware of the complexity hierarchy you intentionally code switch and concretize to reach folks of less complexity. (I might tell a child that a wizard speaks differently to a mouse, a farmer and another wizard.)
The intentional code switching in itself signals complexity. Informed naivete falls in this category (I think) as the person passes from a complex framing to intentionally dwell in the simplification knowingly, but not ironically.